Building a GUI based alternative to PostgREST
TL;DR: PostgREST is amazing when it comes to rapid prototyping, and if the schema is simple enough, it works great in production as well. But on several real apps i kept running into recurring pain points around: (1) Very limited support for nested inserts, (2) URL grammar complexity once SELECT queries get rich, (3) abuse/scraping risk that pushes devs to add an intermediary server anyway, (4) difficult to parse logs for analytics, etc. I am building Querydeck to keep the speed of PostgREST while solving those pain points with a visual, governed workflow.
My experience with PostgREST:
When I first started building iOS apps a decade ago, Swift didn’t exist yet. I was hopping between Objective C on the frontend and Node.js on the backend, wrestling with Knex.js and glue code I didn’t want to write. Then I found PostgREST, and it felt like magic. I could sketch a schema, flip a switch, and get a real API without babysitting a server. For the early, UI heavy prototypes I was shipping, this was perfect: simple tables, straightforward CRUD, zero friction.
As my projects grew up, I kept the habit of always reaching for PostgREST first. But even a little bit of complexity forced me into workarounds that i would later regret. Deeper joins, multi table writes, RPC mess and logging concerns started to pile up. When I moved into consulting, I saw the same pattern across client teams: the initial velocity was incredible, and then the edges showed up in the same places, over and over.
Pain points i have hit repeatedly:
1) Nested inserts = More RPC
Multi table writes? That’s a job for our friendly neighborhood /rpc/.PostgREST is fanastic for simple inserts. Not so much for nested inserts. Lets look at an example with these tables: films, actors, film_actors (many-to-many).
What you want to do: one API call from the client to (a) insert a film, (b) upsert two actors, (c) insert two rows into film_actors to connect the tables.
What you actually end up doing: write a create_film_with_cast(film jsonb, cast jsonb) function in Postgres, wrap the whole sequence in a transaction, and call it via POST /rpc/create_film_with_cast with a JSON body. This works well, but now you’re maintaining server side SQL procedures and an RPC layer instead of a purely declarative REST write.
Illustration:
-- Ideal (not supported natively as a single declarative write)
POST /films (and also create actors, then link)
-- What we ship instead
POST /rpc/create_film_with_cast
Content-Type: application/json
{
"film": { "title": "Heat", "released_at": "1995-12-15" },
"cast": [
{ "name": "Al Pacino" },
{ "name": "Robert De Niro" }
]
}2) URL grammar nightmare:
If the URL needs code review, the romance is over.
Complex screens turn into complex URLs. Try connecting a data table with multiple available filters and sorts across many joined tables and you will quickly see how complicated your "quick and simple API layer" can get. You end up writing and maintaining a custom translator from filters/sorts/paging into a perfectly shaped URL: debugging brittle strings, reviewing unreadable diffs, and teaching non SQL devs a niche dialect. It works, but it replaces backend code with URL choreography. A few of these and it will defeat the original promise of “less glue code.”
URL monster:
/actors
?select=
id,
first_name,
last_name,
birth_year,
films!inner(
id,
title,
release_year,
studios!inner(
id,
name,
country
),
categories!inner(
id,
name
),
awards(
id,
name,
year
)
)
&is_active=eq.true
&films.release_year=gte.1995
&films.release_year=lte.2005
&films.categories.name=in.(Drama,Comedy)
&films.studios.country=eq.USA
&films.awards.year=gt.2000
&or=(
first_name.ilike.*john*,
last_name.ilike.*john*,
films.title.ilike.*john*
)
&films.order=awards.year.desc.nullslast,release_year.desc
&order=last_name.asc
&limit=20
&offset=40
&Prefer=count=exactThe above example shows what a dynamic search and sort URL across two tables can look like. Imagine doing this across 4 or 5 joined tables (!)
3) Abuse/scraping risk → intermediary server
One of the biggest issues i have had is that PostgREST allows the end user to use all visible columns in filters and sorts.
Example: a public companies(id, name, revenue) table powering discovery. I want /companies readable, but never allow revenue in order/where from the public API. Out-of-the-box, if revenue is exposed, URLs like order=revenue.desc or revenue=gt.1000000 are allowed by grammar. I repeatedly end up inserting a small middleware server or shift to RPC to deny certain sorts or rewrite query params.
4) Logs from HELL
I wanted user journeys; I got URL archaeology.
Lets look at another example: i have an entities table that represents companies, investors, and individuals, distinguished by boolean flags (is_company, is_investor, is_individual) or a type enum. That design is great for deduplication and shared attributes, but it makes logs much harder to scan when you expose it through one PostgREST endpoint.
With a traditional REST API it would look simple enough:
# Access logs (RESTful routes)
GET /companies?active=true&limit=50 200 42ms user=123
GET /investors/789/portfolio 200 58ms user=123
GET /people?search=doe&limit=25 200 33ms user=456You can tell which domain is being hit and why. The same use cases turn into long, semantically dense URLs that obscure intent in access logs:
GET /entities?select=id%2Cname%2Cactive&is_company=is.true&active=is.true&order=name.asc&limit=50 200 42ms user=123
GET /entities?select=id%2Cname%2Cinvestments!inner(...long...)&is_investor=is.true&id=eq.789&order=investments.amount.desc 200 58ms user=123
That looks nauseating!
So what is QueryDeck and how does it solve this?
I wanted a tool that could go above and beyond what PostgREST was offering without losing out on what it does well. Which meant building something that offered rapid development, nested inserts, tighter control over filters and sorts, clean urls, etc. QueryDeck is a GUI based API builder for SQL databases. You compose endpoints visually, preview the generated SQL, and publish REST endpoints with governance built in. Features rapid API development, instant deployment, auth/access control, auto docs, versioning, monitoring/logs, and export your API to Github (as a node.js app) if you prefer to self host with production vars.
URL grammar complexity → Visual composition + SQL you can review: Instead of hand crafting select=...nested(...)!inner(...), you click to add joins, choose fields/aggregations, and set filters. You can ship quickly while still reading the SQL before publish.
Safer exposure patterns: You create curated endpoints from saved queries with parameter placeholders: e.g., allow company_id filter, but omit/lock revenue from filter/sort.
Ops & governance: One click deploy to Querydeck’s cloud (beta), with auto generated docs and monitoring/logs for visibility. If you need your own infra or audits, export to a Node.js app.
A nested insert example:
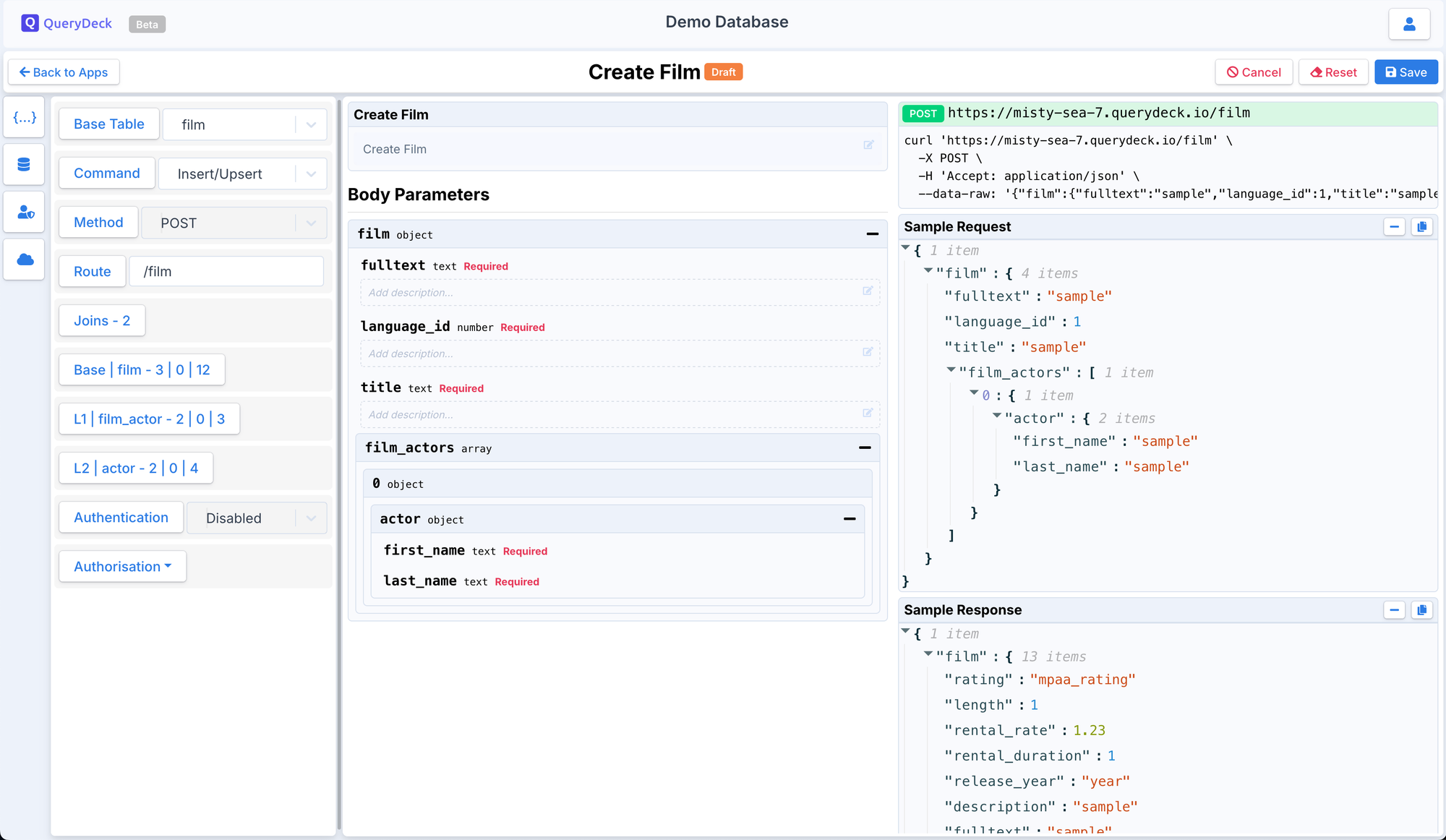
I have been testing it out in production for a couple of products and am happy to report that it has replaced PostgREST for me completely! You can make an API endpoint with nested inserts/upserts in seconds!
However it is still in beta as I iron out bugs and add more basic features. It is completely open source and I have tried to keep installation as simple as possible. In my next post, i will making a video to demonstrate its features better, stay tuned! In the meantime, if you have any questions or suggestions, please contact me at kabir@querydeck.io